16nx, and the value of giving work away
27 January 2025
In September this year, I released a new version of the open source 16-fader MIDI controller I maintain - 16nx. This was a complete redesign of the hardware of the device, and as a result, also a completely new firmware.
Redesigning the device was in one sense, a necessity. 16n - the original faderbank - was designed around the Teensy 3.2, a microcontroller development board that had effectively become end-of-life, and was no longer available. Given that, it was impossible to make the device. If it was to be buildable again, it would need designing around a new part.
If I was going to take on the necessity of a redesign, I may as well also take up the opportunity to make changes or improvements, particularly based on what I’d learned in the years since I’d made those original designs.
I eventually released the project in September 2024 under the same open-source licences as its predecessor. As well as examining the changes in this new version, I wanted to write a little about why I’d give my work away.
The easiest approach to replacing the Teensy 3.2 would be to use its successor, the Teensy 4 - mechanically identical, it’d just take a software rewrite. But it’s vastly overpowered for the relatively simple tasks the 16n does.
And I didn’t really want a drop-in replacement. I was going to redesign the electronics anyway; I had a few goals for them:
- update the analog electronics to improve the control voltage (CV) outputs.
- get rid of the horizontal jacks on the front and rear, to make it easier to push flat against stuff. Connections would just be on the left, right, and top surface.
- change the USB connector to a more robust USB-C connector.
And if I’m redesigning the analog circuitry, maybe a more thorough redesign was in order.
Since I’d designed 16n, small-scale overseas electronics manufacture had become even easier. Assembly of boards, particularly via pick-and-place for surface mount components, was now very accessible and relatively affordable.
The original 16n was a combination of through-hole and large surface-mount components, designed for manual assembly. But in reality, even the chunky surface-mount I’d chosen to go with was fiddly for many people assembling it; the number of bugs that came down to mis-soldered resistors was quite high.
So I had an idea: perhaps all the electronics, including the microcontroller, could be on the board, and assembled in a factory. Save the manual soldering for the chunky through-hole components DIYers are happiest with, and let a pick-and-place do the rest - with cheaper, smaller components. (Tom at Music Thing Modular had already had success with this “easy-bake” approach; it turned out people don’t have to make absolutely every part of something to still get the pleasure of making something).
The project could still be open source, but for people who didn’t want to wrestle with PCBA, I could… sell these “motherboards” myself - maybe to individuals, but perhaps, more likely, to the small manufacturers who assembled faderbanks for clients.
I was attracted to this idea: the project would be easier to assemble, more robust (and less prone to assembly error by hobbyists), and I might see some ROI on the project I’d put so much effort into.
I’d base this new board around the RP2040 chip I was using for so much work now - £1 for the bare chip, a dollar or two for the rest of the required components. It’s far more powerful than low-end 8-but Arduinos, not quite as meaty as a Teensy 3.2 or 4.0, but more powerful than a Teensy LC. And its UF2 bootloader - letting users update their firmware just by copying a file on their desktop - would make end-user firmware upgrades even easier than before, a huge accessibility win.
I wrote the firmware the native C++ Pico SDK. The impact for the end-user was low - they’d get UF2s to upload - but for me was high, letting me work with a powerful toolset and a genuine debugger. I even added a mini JST connector to the board, designed to connect to the official Pico Debug Probe. It was a great help in developing the project, and felt like a good gesture to end users - you should try this approach, there’s a socket ready for you, it works with the official tools.
The trade-off to moving to Pico SDK was that the firmware would get a little less accessible for the hobbyist market. The Teensy project was written in Arduino. When I was working on that, I believed that the more people could contribute to the project, the better, so using a framework popular with makers was important. What I found out was that whilst a lot of people want to contribute bug reports or feature requests, far fewer of them wish to hack on them. No matter how much I would write, sincerely, “that sounds like a great first issue - why don’t you look at that?”, I received relatively few pull requests or forks of the firmware. So I decided to stop making choices about platforms based on what other people might do in the future, and instead choose what I thought was best.
In the end, the assembled 16nx main boards, excluding jacks, switches, and faders, would cost about a third of the equivalent parts - unassembled - for the 16n. And that’s before you consider any savings in terms of how much faster it is to assemble a 16nx - there’s no longer about 60 surface-mount chips and resistors to put on the board by hand.
The electronics redesign took a good while. 16n had been designed inside EAGLE, which was now also end-of-life, and had been subsumed inside Fusion 360 - a good product, but hardly hobbyist-budget. An open source tool made sense for an open source project, so I designed it all inside KiCad - my ECAD tool of choice - keeping the same physical form factor. The layout took a few passes to get right, mainly down to all the routing around the MCU:
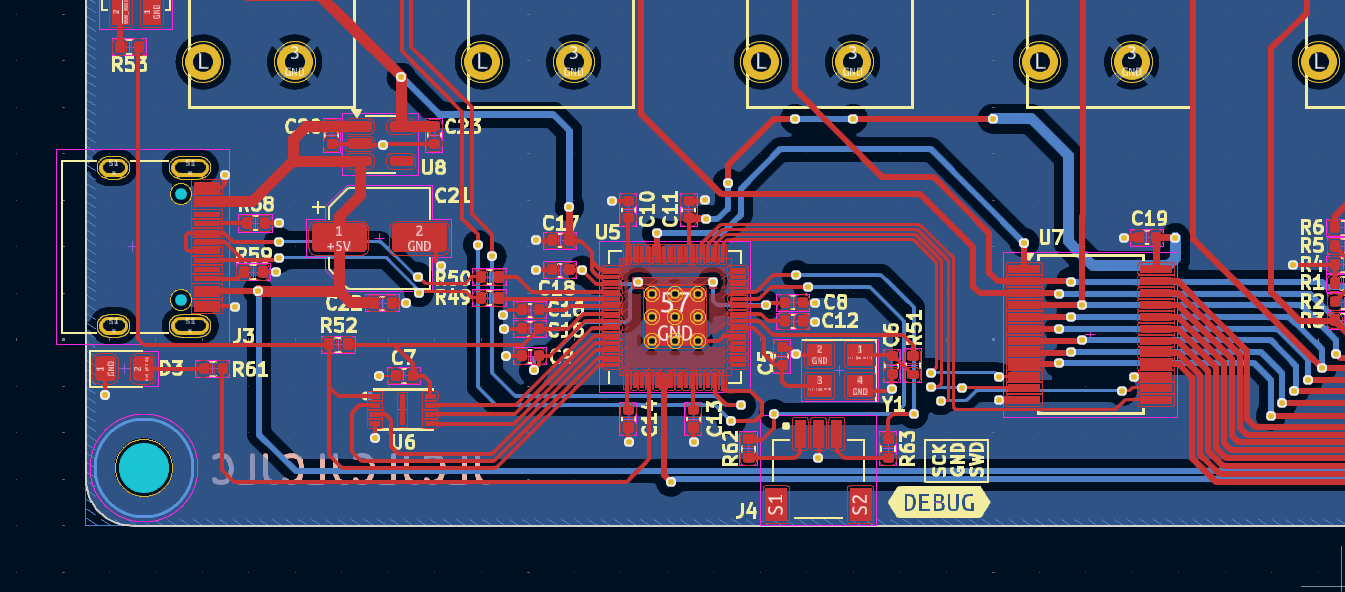 The 16nx PCB layout around the RP2040
The 16nx PCB layout around the RP2040
16n at the time was the most complex thing I’d ever routed. It’s a sign of where I’ve gone since that 16nx isn’t - just - but I’m still very proud of the electronics work on it.
I also spent some time messing around with logos, designing things that would silkscreen nicely with a little inspiration from 90s music hardware…
 A render of the board reverse
A render of the board reverse
With the firmware written, and test boards on my desk, it was time to bring it into the world.
And then… I froze.
I’d fixated on the “selling populated boards” idea as a way of generating a bit of revenue without making “full kits”, or going near sales and support of finished products. I know what I enjoy - and what I don’t - and I find support for end-users stressful (whether or not the support overhead actually materialises - the idea alone gets to me). This other approach would be less stressful than selling complete products, but still find a way for generating ROI.
But I kept getting stuck in a train of thought:
- I don’t want to do customer support at all, really. It’s bad for my brain and stress levels. Even supporting the assemblers/manufacturers I sell to might still be a pressure I wouldn’t like.
- I know enough to know I probably ought to do some form EM testing, even for a bare board. EM testing in the hobbyist industry is uneven, but do I want to take the risk of working out if I’m selling a “partial assembly” or not, and do I want to sell it on, knowing that? Conversely: will EM testing knock any margin on the head?
- This is beginning to look like a lot of work.
- What did I want out of this again?
And the answer is: I want it cheaper, and easier to make, and back in the world again for music makers, and actually, making a small amount of money probably wasn’t my highest priority.
Making a small amount of money would be more expensive, probably, than making no money.
The project was always going to be open source - it’s under an attribution licence that allows commercial derivatives. I wasn’t choosing between an open-source release, and a commercial one. But I was choosing between revenue, and not.
On my birthday, in September 2024, I published the updated 16n website, and made the first open-source release. I igave up on the idea of selling anything; easier to let people who wanted one find a way to bring it to life, just as they had done before. My main goals were met: the faderbank was back in the world, it was now possible to make one again, and it was a bit better designed, even if it did nothing new. It was quite satisfying to quell any “Gear Acquisition Syndrome” with the simple lines in the documentation:
If you already have a 16n that works: you will gain nothing by upgrading. If, however, you’re looking to acquire a faderbank in 2024+, then 16nx is your best route to do so.
There’s a long thread about it on Lines, the spiritual home of the project, and it was once again exciting to see people bringing them to life without me and enjoying the experience. That’s not nothing; I’m proud and buoyed by the response to the project.
It’s not really a “loss” in the slightest. I’ve got a great deal out of the project over the years:
- developing skills and techniques, even within tools I know well.
- facilitating new paying work: the recent Lunar hardware project wouldn’t have been doable without this, and made about as much as I’d have made trying to sell ~100 motherboards.
- building new clients: 16n led to a custom commission from a US composer that ended being a lovely project and a good working relationship.
- the value, to me, of contributing back to a community I care about of musicians and DIY makers.
When I made the decision to give it away, what I felt was relief. It turned out I was agonising over a commercial idea that wasn’t really worth enough to me, and giving that up freed me up in a lot of ways. The final release was smooth and straightforward after that.
Since launch, I’ve largely just let people get on with making them, dropping into Github or forum threads to offer some advice, and in the first week of the year, doing some point releases - upgrading the editor to Svelte 5, building a reasonably sized new feature that’s been requested and getting that ready to launch.
It continues to be a favourite project, and I’m glad that I’ve found a way to keep it going for more years to come, in a way I’m happy with.
Worknotes: Winter 2024
23 January 2025I was working up to the wire in 2024; my main client project wrapped up on December 20th. It was an intense sprint finish to the year, and since then, after some genuine rest, I’ve mainly been getting my feet back under the desk, and slowly trying to bring the shape of 2025 into focus.
What was I up to in the past six-ish months?
Google Deepmind - further prototyping / exploration
I returned to the AIUX team at Deepmind for another stint on the project we’d been working on (see: Summer 2024 Worknotes), taking us from September through to the end of the year. This was meaty, intense, and involving, but I’m pleased to where it got to.
This time, the focus was in two areas: replatforming the project onto some better foundations, and then using those new foundations to facilitate exploring some new concepts.
This went pretty well, and I got to spend some good time with Drizzle (now in a much better place than when I first used it a long while ago; rather delightful to work with) and
pgvector. Highly enjoyable joining vector-based searches onto a relational model, all in the same database.And I think that’s all I can say about that. Really good stuff.
Poem/1 - further firmware development
I continued occasionally work on the firmware development of Poem/1 with Matt Webb. The firmware was in a good place, and my work focused on formatting and fettling the rendering code, and iterating on some of the core code we’d worked on earlier in the year.
16nx
In September, I released a completely new version of the open-source MIDI controller I make. It has no new functionality. Instead, it solves the more pressing problem that you could no longer make a 16n, because the development board it was based on is no longer available. I ported everything to RP2040, and designed it around a single board with all componentry pre-assembled on it. I’ve got a case study of this coming next week, examining what I did and why, but for now, the updated 16nx site has more details on it. Another full-stack hardware project, with equal parts CAD, schematic design, layout, and C++.
Ongoing consulting
I kicked off some consulting work on a geospatial games project, currently acting as a technical advisor (particularly focusing on tooling around geodata), and this should continue into 2025. The way we’re working at the moment is with longer meetings/workshops based around rich briefs: the client assembles their brief / queries as a team, I prep some responses, present back to them, and that opens up future discussion. It’s a nice shape of work, focusing on expertise rather than delivery, and makes a good balance with some of the more hands-on tasks I have going on.
Coming up
2025 is, currently, quiet; slightly deliberately so, but I’m eyeing up what’s next. I’m back teaching for a morning a week at CCI from mid-February; I have further brief consultancy with the games project on the slate; there are few other possibilities on the horizon. Plus, after a crunchy end-of-year on the delivery front, I’ve got a lot of admin to do, and ongoing personal research.
But that’s all “small stuff”.
Like clockwork, here is where I say “I’m always looking for what’s next”. You can email me if you have some ideas. Things I’m into: R&D, prototyping, zero-to-one, answering the question “what if”, interactions between hardware and software, making tools for others to use, applying mundane technology to interesting problems. Perhaps that’s a fit for your work. If so: get in touch.
Worknotes: Summer 2024
18 July 2024Coming up for air.
What happened is: I lined up the Next Thing (as mentioned at the end of last quarter’s worknotes), and then it promptly proceeded to entirely consume my time and brain for the next quarter.
Which is good, from an income-and-labour perspective, but was somewhat to the detriment of the content strategy here, where I’d hoped to be able to write smaller, spikier pieces of content between the studio updates.
So a goal for this quarter: making sure I don’t let client work overwhelm the routines I’d like to establish.
What’s been going on for the past few months?
Google Research/Deepmind AIUX - prototyping and exploration
The previous Next Thing.
Just as the quarter was beginning, I lined up a short, intense prototyping project with the crew at AIUX that I’d previously worked with. They began the project within Google Research, but by mid-project had been reorganised into Google Deepmind.
This made almost no difference to our work, though it did make the “ooh” people make when you tell them who your current client is go up a semitone more than usual (before you tell them you can’t tell them anything else owing to confidentiality).
I spent a couple of months with a motley crew of internal and external folks, pulling together an interesting, full-stack working prototype. Designing interactions, poking technology to see what it feels like, working out how to communicate the new ideas that a piece of software makes possible.
I think all I can say about what we were up to is “stuff to do with vector embeddings”.
The stakeholder feedback at the end of the project was really enthusiastic, and there’s talk of further work on this brief. Very much the right project at the right time.
Creative Computing Institute - end of term
June marked the end of term at CCI, where I wrapped up my fifth year of teaching Sound and Image Processing to first year undergraduates - and which means shortly after I’ve breathed out from the end of class, I have to mark 31 portfolios. It’s a lot to get through, but I’m always surprised and delighted by the places some students will take me, and it’s those moments that keep me going as I work through reading and executing a lot of Processing.
When I tell people I’ve been marking, they often ask about the impact of ChatGPT on my results. All I can say is: yes, we are educating in the age of ChatGPT now. (Other LLMs are available; I’m using ChatGPT as shorthand for LLM chatbots you ask for answers).
We don’t have a problem with students using LLMs; they’re a tool like any other, and for students less confident in a second (or third+) language, or students newer to programming, they can be a confidence-booster. We ask students to cite them just like any other source. (I usually teach citation by suggesting you quote as little as possible, and then, if you are uncomfortable revealing the size of your quotation, perhaps that’s an indication for you to quote less.)
Despite this, I believe I had many students who used ChatGPT and didn’t cite it. You can’t prove it, but there’s a… vibe? Smell? It never feels like plagiarism or copying; it’s more like a number of students all sharing the same tutor, whose personal style and predilections keeps appearing in their work. The programming equivalent of delvish, perhaps. (I had lots of
(int)style casting this year, for instance, which seemed like a tic given I’d never really introduced it, and Processing’s built-inint()function is probably more intuitive).But there are also thoughtful uses of these tools. I’ve had students submit entire transcripts of their conversations with ChatGPT, for instance, which has been good: they showed they had the knowledge necessary to ask meaningful questions and build on them, and showed how they refined their own knowledge in the dialogue. I’ve also had students describe processes - one talked about submitting his code to ChatGPT and then asking how would you improve this? which is an interesting approach to virtual pairing/refactoring, and shows a good degree of insight - not to mention curiosity.
With marking done, I rounded out the year by going to the student festival, the end-of-year show of work. This was the second year where students I’d taught in their first undergraduate year were graduating. It was hugely enjoyable and rewarding to see how they have developed, and how they are expressing their ideas and interests in creative computation a few years down the line.
Lunar - hardware/software refinements
I’ve just kicked off a very short engagement with Lunar - some further refinements to the LED interaction tools work that we did. Some new hardware, and a revision to both firmware and browser tooling has made for a busy week back leaping between C++ and Typescript.
What’s next?
The next few months are coming into focus now. August looks a little less frantic, with some smaller projects slotting into the schedule alongside a deliberate amount of Slack, and there are rumblings of larger work in September that could keep me busy for several months.
Meanwhile there’s admin to be done, and some plates to keep spinning, as well as making sure I return to some Process Notes here. And so: onwards!
Worknotes: Spring 2024
26 March 2024A quarter has passed since the last worknotes; now’s a good time to reflect on what I’ve been up to.
Lunar Energy
Two pieces of work this quarter with the Design team at Lunar. I wrapped up the project mentioned at the end of 2023 in January, as I’d expected. A second project emerged in March, exploring generative/systemic graphic and motion design, and that wrapped that up this week. There should be things I can point at and say more about very soon.
Creative Computing Institute
It’s spring break currently - the gap between the second and third terms - at CCI. I wrapped the first half of the first year undergrad class I teach; I’m back in early April for the summer term, when we’ll be looking first at audio, and then at particle systems. I particularly enjoy the latter - it’s such a rich and fun topic to play with in code.
Work with Acts Not Facts
A small project with Matt W over at Acts Not Facts, which there’s not much to say about right now, but had some good in-room collaboration. Oh, and his AI Clock - Poem/1 - that I’d previously done some firmware work on - hit its goal on Kickstarter (and then some - 117% funded), which is excellent news, and means that will be getting into the world.
Ongoing consulting
Technical/strategy consulting with the very early-stage startup I’m advising continued; just this week I’ve been helping them get a prototype of a core concept up and running, so that they can evaluate and test it with real users.
I also had a catch-up about a games project I’d been lightly advising on; they’ve got funding, which means there’s some thinking/consulting/plotting - and maybe prototyping - to come in the next quarter.
Content strategy for this site
One of the outcomes of some recent coaching with Andrew Lovett-Baron was overhauling how I communicate a bit; trying to build up a cadence of content here again. Weeknotes served me well for so long, but they are had to maintain in fallow periods, or in long periods of NDA’d work. So they fell by the wayside a bit.
I’ve decided to try to move to a more programmed set of formats: regular-ish (eg, quarterly) Worknotes that describe recent output and projects; Process Notes that talk about studio practice and process, not necessarily focused on a recent project, but as a way of demonstrating my own practice and approach; and writing about One Thing from time to time, as a way of sharing insight and critique - as well as the kinds of things that interest me as a designer/technologist.
So far: I think it’s going OK?
Spending time with peers
I’ve spent a bunch of Q1 2024 just taking time to catch up with peers and colleagues to compare notes on… this and that. That’s been, as usual, restorative. I’m writing this to remind myself - and you, reader - that it’s worth expending the effort on. As a sole practitioner, it’s worth spending time maintaining the collaborative/conversational/social aspects of work that just aren’t there when you’re on your own most days. Q1 was a good period to recharge in.
What’s on the horizon for the coming months: wrapping this term of teaching; beginning consulting on the above games project; some ongoing hardware prototyping/exploration; lining up the Next Thing. Onwards.
Process Notes: Jigs and Things
12 March 2024
This is a recent prototype.
It’s a custom PCB that takes a single Cherry MX style keyswitch, with a resistor and an LED positioned to illuminate the keycap, broken out to pins. That’s it.
It’s part of a larger prototype, that involves buttons and controls and many chips. For a while now I’ve taken to prototyping quite large electronics projects in their full, final form. That means getting a large board made, fully populated with all parts, and then debugging it. It should work first time, but that’s not always the case, and a mistake can mean another costly revision.
This project has more unknowns in it than normal: new parts (like these keyswitches); new ICs; a UI that is still very much up in the air (and involves keys, knobs, and chording). So I’m prototyping it on a breadboard to begin with.
Breadboards often mean a lot of dangling jumper wires and bare components. But making small custom modules like the keyswitch module above can make your life a lot easier. In this case, ten small prototype boards to hold a single key were a few pounds in a recent larger order of PCBs. I’ve used hot-swap sockets so I can re-use the switches themselves in later work. The passive parts and pinheader cost pennies.
But: now I’ve got ten light-up mechanical keys to prototype with, and to reuse in later prototypes.
The keyswitch board is a particular kind of prototype that I build a lot, whether it’s in hardware or software: a small reusable atom, beyond bare wires, but not of use on its own. Crucially: it’s just for me. It might have utility to somebody else, but that’s by coincidence, not design. As a module, it’s not quite like the development boards in my prototyping drawer from firms like Adafruit and Sparkfun. It’s a more low-level building block.
I usually call these kind of things test harnesses or jigs. Here’s another jig, perhaps a more traditional use of the term:

This is a small 3D printed jig that assists me in placing an adhesive rubber foot in the correct spacing away from the corner of an object.
It took a few minutes to design - project the outline of the object, define an offset, extrude upwards, a quick subtraction - and about 15 minutes to print. It does one job, for one particular project, but it made positioning 28 rubber feet quick and repeatable.
Making a thing is usually about also making the tools to make a thing. Test suites; continuous integration; preview renders; alignment jigs. They’re as much part of the process as making the thing itself, and they are objects that show the growing understanding of the current act of making: you have understood the work well enough to know what tool you need next to make it; to know what tool you need next to think with. Making is thinking.
The switch jigs helped me understand how many buttons I’d need, what it’d be like if they could light up, whether it’d be useful to have a ‘partially lit’ state. They also helped me do this work without wasting money on permanently soldered switches. The foot jig came out of need: I had placed enough feet by hand to know that a more professional outcome could be achieved in half an hour of CAD and modelling, time that would be somewhat recovered by the quicker, more professional alignment process.
I love making tools. I particularly love making tools for other people to use and create with. But to only celebrate that kind of toolmaking obscures a more important kind: the ongoing, ephemeral toolmaking that is part of making anything. Making A Tool is not a ‘special’ act; people do it all the time. I think it’s important to celebrate the value of all the tools and jigs and harnesses that are essential to the things we make… and that also are inevitably thrown away or abandoned when the thing they enable comes into the world.
They’re process artefacts: important on the journey, irrelevant at the destination. I have drawers and project boxes and directories and repositories full of them, for all manner of projects - whether they are made of hardware, or software, or ideas, or words. They seemed like a good subject for some Process Notes.
One Thing: Synthstrom Deluge Crash Reports
19 February 2024I was really taken with this, which @scy (Tim Weber) posted on Mastodon the other day:
The Mastodon post is very clear, so to quickly summarize: The device has crashed; it’s shared its stack trace optically, using the LED button matrix on the device. To share that stacktrace with the development team, the end-user only has to post a photograph of it to the development Discord, where an image-analysing bot decodes it and shares the stacktrace line references as hexadecimal. Neat, end-to-end stack-tracing, bridging the gap between one hardware device and the people who develop its firwmare.
This feature is particular to the “community firmware” available for the Deluge. Designed by Synthstrom Audible in New Zealand, the Deluge is a self-contained music device - a ‘groovebox’ - that was originally released in 2016. In 2023, Synthstrom released the firmware for the device as open source, and a community has emerged working on a parallel firmware to the ‘factory’ firmware, with many features and improvements. Synthstrom can concentrate on their core product, and on working on maintaining and improving the hardware; the more malleable part of the device, the firmware, is given to the community to be more malleable.
Why Share This?
Firstly, as the comments in @scy’s original post point out: this is very cool. The crash itself goes from being an irritation to a shareable artefact - look at what this thing can do! I am pretty sure if that if I owned one of these and it crashed, I would share a similar post with friends.
I particularly like it, though, for its transparency. When devices with embedded firmware fail, it can be difficult to work out why, or what has happened - and if the device has no network connection (usually completely understandably!) there’s rarely a way of sharing that with the developer. By contrast, this failure state makes it clear that something has failed and it’s OK to share this fact with the user - because the developer is also asking to be told.
The Deluge makes this reporting even more challenging in one aspect: whilst the Deluge now ships with an OLED screen, original Deluges only have the RGB matrix and a small seven-segment numerical display for output. There’s no way of displaying any text on these earlier models!
But by encoding the stack trace as four binary numbers, it can be displayed on the screen as four 32-bit numbers. Sharing the stacktrace is left to the owner - and can be done with a ubiquitous phone camera. Finally, decoding the stack-trace is the responsibility of the bot in the Discord channel - no need to involve the end-user in that necessarily. The part of this process that runs on the embedded firmware is the least complex part of the process; networking is left up to the user’s phone, and the more computationally complex decoding is left to server-side code.
This feature is also an appropriate choice for the product. Sharing the stack trace to Discord might be a little too involved (or “nerdy”) for some deices, for but for an enthusiast product like the Deluge, with an involved and supportive community, it feels like a great choice.
And it gives the user agency in the emotional journey of a crash. Most of use have clicked “send” on stack traces going to Apple, Microsoft, or Adobe, and then perhaps just given up on the idea that anyone ever sees our crash logs. But here the user is an active participant in the journey: if they choose to share the stacktrace, they have visibility on the fact it’s been seen and decoded in the Discord channel. And now that they’ve shared it to a social space, they have created an artefact to hang future conversation about the crash off - and where they may even learn about future fixes to it.
The feature is neat, and a talking point - but it’s also interesting to see how a moment of software failure can be captured without a network connection on the device, shared, and ultimately socialised. (It also beats the IBM Power On Self-Test Beeps by a long stretch…)
One Thing is an occasional series where I write in depth about a recent link, and what I find specifically interestind about it.
Process Notes: Twenty Years of Not Writing Python
12 February 2024I recently shipped some client work - a small prototyping project - written in Python. Which is surprising, given I would say - if asked - that “I don’t write Python“.
A lot of people write a lot of Python these days. It’s a common teaching language; it’s a lingua franca for machine learning and data science; it’s used as a scripting language for products I use such as Kicad or Blender. But it’s passed me by. I first wrote Ruby in 2004, which I still love, and that’s served my needs as a general-purpose scripting language, as well as a language for building web applications (with Rails). These days, I’ll also write a lot of Typescript. I don’t really need another scripting language.
Given that “I don’t write Python“… why did I just ship a project in it, and how did I do that?
First of all: why Python for this project?
I needed something that could write to a framebuffer from a command-line, running in an event-driven style. I also needed something that could be used cross-platform, and wouldn’t be too hard for anyone else to pick up. Given this was a prototyping project, ease of manipulation and modification were important, so an interpreted language with no build step would be helpful. As would good library and community support. pygame looked like it would be a very good fit for our project.
Whilst I wouldn’t admit to writing Python, it turns out I had a fairly strong ambient knowledge of it already. I knew its basic syntax, and was used to its module-style imports via Typescript. I was well aware of its lack of braces and significant whitespace. And someone who loves functional-style code, I was already a big fan of was list comprehensions.
I paired that ambient knowledge with a couple of core programming skills.
Firstly : my experience of other event-driven languages and platforms (like Processing, p5js, and openFrameworks) meant I was already familiar with the structure the code would need. An imperative, event-driven structure is going to be pretty similar whether you’re writing in Processing or pygame; I tend to write these with as small a main loop as possible, and then core functions for “set up all the data for this frame” and “render this frame”, broken down as appropriate. You can smell the porting in my code, plus I’m sure I could be more idiomatic, but structure is structure; this meant we began with solid foundations.
Next: reading documentation. pygame has good documentation, and thanks to its maturity, there’s a lot of online resources for it - not to mention excellent resources for Python itself. That, combined with good experience of usefully parsing error message got us a long way.
Modern tooling helps a lot:
- language support in editors/IDEs has gotten really good; the Language Server Protocol means that developer support for interpreted languages is better than it’s ever been. More than just spicy syntax-highlighting, its detailed and comprehsnive support is exactly what you want as an “experienced, but not in this language” developer.
- “What about ChatGPT?“ This is not an article about how I wrote code without knowing how, all thanks to ChatGPT, I’m afraid. But one thing I have begun to occasionally use it for is as a rubberduck; a “Virtual Junior Developer.” “I’m looking for an equivalent to Ruby’s
xin Python. Can you explain that to me, knowing that I’m an experienced Ruby developer?“. It usually won’t give me precisely what I’m looking for. But it will give me something in the ballpark that suddenly unblocks me - much like a good pairing partner might. Sometimes, that’s why I need. - A rubbderduck I find much more useful is Github Copilot. Again, I don’t think its strength is the “write code for me” functionality. Instead, I most like its ability to provide smart, contextual autocomplete. That’s doubly useful in loosely typed languages, where language servers can be limited in their recommendations in a way that LLMs aren’t limited by. I’m particularly grateful for Copilot as a solo developer; it feels like a pairing partner chipping in with ideas, which, even when they’re not right, at least steer me in a new direction. I’ve found Copilot particularly speeds development up later on in a project. As the codebase gets larger, its intuition becomes more developed.
The combination of core competencies, modern tooling, and a well-established platform enabled us to not only motor through the initial porting process, but achieve our further goals, with space and time left for polish and improvement within the budget. The final codebase met the client’s needs: it worked well cross-platform, was straightforward (thanks to
virtualenv) to get up and running on a colleague’s development computer, and is a good foundation for future work.
Programming work - I hesitate to say “creative programming” because all programming is creative - is about much more than just ‘knowing a language’, and this project was a great example of that.
Much more important is knowing how to learn new languages (and how you best learn new things); understanding patterns common to styles of language; maintaining good code hygiene and great documentation; and finding ways to steer yourself in the right direction - whether that’s a partner to pair with, the right developer tool, a good online resource, or even a modern application of AI.
My evaluation at the beginning of the project had been validated. As I’d suspected, actively choosing to work in a new-to-me platform was not a risk. It turned out to be exactly the right tool for the job - a prototype where speed of iteration and flexibility were highly valued.
That evaluation comes down to something I often describe as a sense of smell; a combination of expertise, personal taste, and ‘vibes’. Perhaps it’s easier just to call that experience. It turns out that “twenty years of writing software” beats the fact that almost none of it has been Python.
We wrapped this small project last week, and I enjoyed my exposure to Python as a more experienced developer. I also valued being reminded me of what experience feels like, and what it enables: good judgment, flexibility, and focusing on the project’s outcomes, rather than getting lost in implementation.
Worknotes: end of 2023 wrap-up
8 January 20242023 was frustratingly fallow, despite all best efforts. Needless to say, not just for me - the technology market has seen lay-offs and funding cutbacks and everything has been squeezed. But after a quiet few months, the end of 2023 got very busy, and there’s been a few different projects going on that I wanted to acknowledge. It looks like these will largely be drawing to a close in early 2024, so I’ll be putting feelers out around February. I reckon. In the meantime, several things going on to close out the year, all at various stages:
Lunar Design Project
After working on the LED interaction test harness for Lunar, I kicked off another slightly larger project with them in the late autumn. It’s a little more of an exploratory design project - looking at ways of representing live data - and that’s going to roll into early 2024. More to say when we have something to show - but for now it’s a real sweetspot for me of code, data, design, and sound.
Web development project “C”
More work in progress here: a contract working on a existing product to deliver some features and integrations for early 2024. Returning to the Ruby landscape for a bit, with a great little team, and a nice solid codebase to build on. Lots of nitty-gritty around integrating with other platforms’ APIs. This is likely to wrap up in early 2024.
This and the Lunar project were primary focuses for November and December 2023.
Nothing Prototyping Project
Kicking off in December, and running into January 2024: a small prototyping project with the folks at Nothing.
AI Clock

A short piece of work for Matt Webb to get the AI Clock firmware I worked on in the summer up and running on the production hardware platform. The nuances of individual e-ink devices and drivers made for the bulk of the work here. Matt shared the above image of the code running on his hardware at the end of the year; still after all these years of doing this sort of thing, it’s always satisfying to see somebody else pushing your code live successfully.
Four projects made the end of 2023 a real sprint to the finish; the winter break was very welcome. These projects should be coming into land in the coming weeks, which means it’s time start looking at what 2024 really looks like come February.
Recent and ongoing work: Community Connectivity
8 September 2023I’ve begun a small piece of ongoing consultancy with Promising Trouble on their Community Connectivity project. It’s a good example of the strategy and consulting work I do in my practice, alongside more hands-on technology making.
Promising Trouble is working with Impact on Urban Health on a multi-year partnership to explore how access to the internet impacts health and wellbeing. I’ve been working in an advisory capacity on a pilot project that will test the impact of free - or extremely affordable - home internet access.
Our early work has together has narrowing down how to make that happen from all the possibilities discovered early on in the project. That’s included a workshop and several discussions this summer, and we’ve now published a blogpost about our some of that work.
We’ve made some valuable progress; as I write in the post,
A good workshop doesn’t just rearrange ideas you already have; it should also be able to confront and challenge the assumptions it’s built upon.
Our early ideas were rooted in early 21st-century usage of ‘broadband’, a cable in the ground to domestic property - and that same concept underpins current policy and leglisation. But in 2023, there are other ways we perhaps should be thinking about this topic.
The post explores that change in perspective, as well as the discrepancy between the way “broadband” provision and mobile internet (increasingly significant as a primary source of access for many people) are billed and provided.
I hope that we’ve managed to communicate a little how we’re shifting our perspectives around, whilst staying focused on the overall outcome.
My role is very much advice and consultation as a technologist - I’m not acting as a networking expert. I’m sitting between or alongside other technology experts, acting as a translator and trusted guide. I help synthesise what we’re discovering into material we can share (either internally or externally), and use that to make decisions. Processing, thinking, writing.
When Rachel Coldicutt, Executive Director at Promising Trouble, first wrote to me about the project, she said:
“I thought about who I’d talk to when I didn’t know what to do, and I thought of you.”
One again, a project about moving from the unknown to the unknown.
The team is making good progress, on that journey from the unknown to the known, and I’ll be doing a few more days of work through the rest of the year with them; I hope to have more to share in the future. In the meantime: here’s the link to the post again.
New case study: Lunar Energy LED interactions
31 August 2023I’ve shared a new case study of the work I did this summer with Lunar Energy (see previous worknotes).
As I explain at length over at the post, it’s a great example of the kind of work I relish, that that necessarily straddles design and engineering. It’s a project that goes up and down the stack, modern web front-ends talking to custom hardware, and all in the service of interaction design. Lunar were a lovely team to work with; thanks to Matt Jones and his crew for being great to work with.
Recent strategy/consultancy work
18 August 2023In the past couple of years I mentioned working on an early-stage startup project I codenamed Wrekin (see relevant blogposts) - in part because it hadn’t launched out of stealth. Since then lots has moved on, not least the launch of the product as Castrooms.
Castrooms brings the energy of a crowd to music livestreaming. It’s a streaming platform designed first and foremost for music - for both performers and fans. Audience members watch streams with their camera on: performers have a crowd to perform and react to, and fans can go to shows and performances with their friends, the live music experience of “small groups as part of a bigger group”.
The product has taken off since I worked on those early prototypes. Back in 2021, I built just enough to help them validate the idea, work out what was feasible with available technology, and understand what would need to come next.
Since then, they’ve fleshed out the offering, developed the branding, greatly expanded the technical platform, run many test parties, forged relationships with DJs and musicians, and raised more funding. Since I last wrote there’s been a little more advisory and consulting work with them. It’s been exciting to see the product take off, and hear the team tell me about their growth and successes.
I spent some time this between 2022 and 2023 working with a very early-stage health startup, delivering a few strategy workshops.
This consultancy work began with a request for a single day’s workshop. I immediately suggested this would better be spent as two half days. Anyone who’s workshopped knows the “4pm lull” well - but I also believe that a break between the workshops leads to more effective outcomes. Yes, participants get a break, and can come back refreshed - but it also forms a neat point to do any ‘homework’ required. Sometimes, doing some independent research, confirming some facts, or thinking through ideas with other people outside the process, is what’s needed to make any decisions or move things forward. That’s better done outside the workshop space. We returned to the second half of the workshop much more focused, and with ideas that emerged in the first half already fleshed-out and ready for deeper discussion.
A follow-up workshop some time after the initial engagement was similarly productive. It was also rewarding - it was great to see how much the product had developed in the months that had passed, how many ideas born in the first workshop were being validated or developed in the world, with customers, and how the offering was being focused.
Summer 2023: what's on the slate?
1 August 2023What’s been going on in the studio this summer?
UAL Creative Computing Institute
I finished another term of teaching at CCI: as usual, teaching the first year BSc Creative Computing students about Sound and Image Processing - an introduction to implementing audio and graphics in code. That means pixel arrays, dithering, audio buffers, unit generators, building up to particle systems and flocking - all with a focus on the creative application of these topics. It was great to see where the students had got to in their final portfolios - some lovely and surprising work in there, as always.
A reminder: why do I teach alongside consulting and development work? I have no employees, and so this is my way of sharing back my knowledge and developing new talent - as a practitioner-teacher, and as someone who can share expertise from within industry back to students looking to break into it.
I value “education” as an ideal, and so spending about half a day a week, around client work, for a few months, to educate and share knowledge feels like a reasonable use of my time. It’s also good to practice the teaching/educating muscle: there’s always new stuff to learn, especially in a classroom environment, that feeds into other workshop and collaboration spaces.
AI Clock P2

Matt's photo of P2 on his shelf I spent a short while working with Matt Webb on “P2” - prototype 2 - of his AI Clock. He’s written more about this prototype over at the newsletter for the project - including his route to getting the product into the world.
This prototype involved evaluating a few different e-ink screen modules according to Matt’s goals for the project, and creating a first pass of his interaction design in embedded code. I built out the critical paths he’d designed for connecting and configuring the clock, as well as integrating it with his new API service. The prototype established feasibility of the design and, during its development, informed the second version of the overall architecture.
Since I’ve handed over the code, he’s continued to build on top of it. I find this part of handover satisfying: nothing is worth than handing over code and it sitting, going stale, or unmaintained. By contrast, when someone can take what you’ve done and spin it up easily, start working with it, and extending it - that feels like part of a contracting/consulting job well done: not just doing the initial task, but making a foundation for others to build on. Some of that work is code, some of it’s documentation, and some of it’s collaboration, and it’s something I work towards on all my client engagements.
Lunar Energy
I’ve been working on a small project with Lunar Energy. The design team were looking to prototype a specific hardware interaction on the actual hardware involved. I’ve been making hardware and software to enable the designers to work with the real materials in a rapid fashion - and in a way that they can easily share with technical and product colleagues.
It’s been a great example of engineering in the service of design, and of the kind of collaborative toolmaking work I both enjoy and am particularly effective at. I’ve been jumping back and forth between browser and hardware, Javascript and embedded C++, and I think we’ve got to a really good place. I can’t wait to share a case study.
Promising Trouble
Finally, I’ve started a small consultancy gig with Promising Trouble on one of their programmes, spread over a few days this summer, and then a few more towards the winter. My job here is being a technological sounding board and trusted advisor, to help join the team join some dots on a project exploring a technological prototype to address societal issues. A nice consultancy project to sit alongside the nitty-gritty of the Lunar work.
and…?
And what else? I have capacity from early August onwards, so if you’d like to talk about opportunities for collaboration or work, now is a great time to get in touch. What shape of opportunities? Right now, my sweet spots are:
- invention and problem-solving: answering the questions what if? or could we even?; many of my most successful and impactful projects have begun by exploring the possible, and then building the probable.
- “engineering for design” - being a software developer in the service of design, or vice versa; the technical detail of platforms, APIs, or hardware is part of what we design for now, and recent work for companies like Google AIUX and Lunar has involved straddling both worlds, letting one inform the other, working in tight cross-functional teams to build and explore that space, and ultimately communicating all of this to stakeholders.
- projects that blend the digital and physical. I’ve been working on increasing numbers of projects that straddle hardware, firmware, and desktop or browser software, and the interactions that connect all of them.
- technology strategy; that might be writing/thinking/collaborating, or building/exploring, or first one, then the other; I’ve recently done this with a few early-stage founders and companies.
- focused technical projects, whether greenfield or a companion to existing work - that might be adding or integrating a significant feature, or building a standalone tool. I tend to work on the Web, in Ruby, Typescript and Javascript (as well as markup/CSS, obviously). I like relational data models, HTTP, and the interesting edges of browsers.
- and in all of the above: thinking through making, informing the work through prototypes and final product builds.
You can email me here if any of that sounds relevant. And now, back to the desk and workbench!
A year with Svelte(Kit)
23 January 2023I’ve spent much of 2022 working with SvelteKit as one of my primary development environments. Kit hit its 1.0 release in December 2022. I’ve spent some time evangelising it to developer colleagues, many of whom may not have encountered it, and a year with Kit feels like a good time to summarise that time, and explain why I’m spending so much time with it.
First, we should start with Svelte.
Svelte
Svelte is a reactive component framework for building web front-ends. Think of it like React or Vue. To the eye, it resembles Vue much more than React: it uses single-file components, broken into script, markup, and styles. Unlike Vue, it uses a templating language with specific tags, rather than ‘special’ attributes on HTML elements.
It’s quite straightforward, in that it doesn’t do a great deal. It provides a way of building components, passing data to them, and reacting to changes in data. It has some unusual syntax, but throughout, it tries to ensure all its syntax is valid Javascript syntax.
Throughout the entire project, it’s clear that where possible, it wants to fit into the web as it is, using standards where it can, and syntax or patterns developers know.
There are couple of things that might surprise you coming from other frameworks.
Firstly: reactivity uses two-way binding. Obviously, this is an easy shortcut to a footgun, and might sound smelly or unsafe to you. But Svelte makes it safe, and it leads to terser syntax and makes it easier to write code that states your intent in a literate way, rather than dancing around one-way React-style binding.
Secondly - and this is partly why that two-way binding is safe: Svelte is a compiler. When you visit a site that uses it, you’re not downloading all of Svelte to use the page; Svelte compiles the site down to only the script needed to make it run. And in doing so, throws out all the Svelte-specific syntax or code, makes sure you’re not doing anything impossible. It emits compact, fast code.
(This is all because, thirdly, Svelte is really a language)
If that’s Svelte, what is SvelteKit (or “Kit”) for short?
SvelteKit
SvelteKit is to Svelte as Next is to React, or Nuxt is to Vue. It’s a full-stack, isomorphic framework. That means: you write your code once, but it could run on the front-end or back-end.
By default, when you hit a URL, the server renders that page, and serves it to you - and then future navigation uses the History API and requests just JSON from the backend, rendering the front-end reactively. The documentation doesn’t really use the phrase “full-stack”, and perhaps that term has served its purpose. The technology skews towards the front-end, as most site frameworks built on top of component frameworks do - but it’s definitely everything you need to make a site. The answer to “but where does it run” is “yes”.
In a Kit site, the front-end is made of Svelte components - all pages are, in fact, themselves just Svelte components - and the back-end is Javascript. As well as a routing system for displaying components, Kit offers ways of building server-side only backends, loading code to pull data from the back-end, and building the site to run on a range of deployment environments (more on this later).
At this point I imagine somebody sucking their teeth and having opinions about Single-Page Apps (I sure do). But SvelteKit is much more interesting than that.
SvelteKit sites build using an adapter system. Adapters transform your development code to code suited for production deployment in a particular environment. The same code can be deployed to different infrastructures with different adapters.
In development, you work against an Express server, and you could make a production build that uses this approach using
adapter-node, emitting an app you can just run withnode index.jsin yourbuilddirectory. Put it onto Heroku, or behind an nginx proxy, and off you go.Or maybe you just want an entirely static site - you have no dynamic code at all, and could bake the whole thing out.
adapter-staticwill let you do this.Calculate the routes you want to prerender, and build the whole site to a directory you can host on S3 or Apache. You can even tear out all the rehydration and build a site that has no Javascript in it at all.But most interesting are the adapters for modern “JAMstack” hosts, like Netlify or Vercel. Build a site with
adapter-netlifyand all your static pages will get prerendered as before… and your dynamic pages, or back-end endpoints, will all get turned into (eg) Netlify Functions, to run on Lambdas as appropriate.(I like this because it pushes back against one of my issues with JAMStack sites: you control the front-end, and when it comes to anything resembling a back-end, you just give somebody else your credit card details and use their API. Kit makes it easier for front-end-preferring developers to write their own tiny parts of back-end code, integrated into modern front-end-preferring hosting platforms. Obviously you’ll still need some kind of storage, but I like that you’re not having to jump between cloud/lambda functions in one place, and front-end code in another: your application should be all one thing, and you should write as much of it as you can).
Whilst there are always going to be host-specific issues, this somewhat decouples application design from application build; a kind of future-proofing (not to mention the ability to change your mind later, as a static site develops more dynamic features). You can even throw away all the static pages and dynamic routing and make a classic SPA that lives only in the client, if you really want to.
Standards all the way down
But what I enjoy most is how “of the web” it all feels. One of Kit’s key design philosophies is using standards when they exist. That means
fetchthroughout, polyfilled on the server, natively in the client; that meansRequestandResponseobjects on raw server endpoints; that means Form Actions that, by default, simplyPOSTto an endpoint and redirect, before the documentation goes on to show you how theenhancedirective can be used to start dynamically updating the page without a reload for those users who have scripts enabled. As a developer who likes his POST and GET, this is the way. A user on the discussion forums was trying to work out how to call server-side functions from the client, and I pointed out they just had toPOSTto their paths; I could feel their eyes bulge a little, before they then realised that perhaps this was how it always should be.The tooling is particularly good - especially its use of static typing, and its VS Code extension. It’s lovely to return a typed object on the serverside, and have your front-end components pass that typing all the way down - or to raise an IDE error when they’re not quite getting what they expected.
And integrating SvelteKit with existing code and libraries is lovely, because Kit does so little. From the outside, it might not look like the ecosystem is nearly as big as React’s. But that doesn’t necessarily matter: bringing existing libraries into Svelte seems much easier than bringing them into React land. A colleague I’d introduced to SvelteKit confirmed this after doing exactly that on a project not two months after starting using it. “It turns out I didn’t need the libraries,“ he said, and just wrote his own integration with a handful couple of lines; a far cry from trying to find yet another plugin to
useSomething.One reason I often pick it is the familiarity of all the moving parts. There’s something about the syntax that makes it so easy and welcoming to pick up for newcomers. I pick Svelte often because I can get other developers who know HTML/CSS/JS|TS up and running on it really fast. It’s even more ‘natural’ to work in than Vue, and especially so than JSX/React.
And finally, the reason I feel confident in it is… I like the taste of its core team. Rich Harris - ex-New York Times, now at Vercel - is thoughtful, considered, and has what I think is good taste. When it comes to frameworks, taste is important: if you don’t agree with the core philosophy of the project, which inevitably means the taste of the project leads… you likely never will. But I do - that focus on straightforward tools to build moderate-sized products, focusing on One Way To Do Things, an emphasis on excellent documentation and (especially) interactive tutorials, and above all, something that feels more like the Web: standards all the way down.
I’ve used it recently on a few projects:
- a blog rewrite, handling thousands of pages across 10 or 12 template files; primarily focusing on static delivery of key pages, and then dynamically rendering the long tail of the site
- a content site that, on the content⟷software scale, was firmly at the ‘content’ edge, having been written in Jekyll. Rewriting it in Kit allowed us to move it a few notches towards software. It became easy to, in a mainly Markdown-driven site, still embed dynamic or interactive components inside Markdown articles - or reach out to external services for certain components based on page-level metadata. We began rendering this statically, and moved to using a dynamic renderer when the ability to serve it statically wasn’t quite as ready as we hoped.
- highly interactive prototypes of mobile UI and apps, using all the features of a modern browser (touch events, MediaRecorder and MediaStream APIs, gestures) to build a rich, interactive prototype.
It works well for all of these. In particular, its static-generation performance is… pretty competitive with some of the dedicated JS Static-Site Generators.
Mainly, though I like using a modern, isomorphic-style component-based web framework that still feels of the web, still interested in pages and URLs and HTTP and accessibility, whilst allowing me to use modern tooling and the reactive pattern. I also continue to love the enthusiasm for it that everyone I share it with has. It’s not my only hammer, nor is it the only thing I plan to use going forward (and I’m still going to reach for Rails when I’ve got CRUD and data-heavy applications) - but it’s been a great tool to work with this year, and I hope to share it with more developers in time, and work with it again.
Spring 2022 Worknotes
20 April 2022What happened was: I meant to write about the end of 2021 before a big project in 2022 kicked off. And instead, 2022 came around, the project kicked off hard and whoosh it’s now the Spring.
I have been quiet here, but busy at work. And so, here we are.
What’s been going on?
Wrekin wrapped up in the autumn, as expected. I completed my final pieces of documentation, and handed them over. Recently, I’ve been doing a small amount of handover and advisory work with their new lead developer as they push through the next phase of the project. I’m excited to see where they’ll take it.
The small media project I mentioned last time came to fruition. Codenamed Hergest, it was a proof-of-concept to explore if a product idea was achievable - and feasible - within a web browser. Rather than prototype the whole product, I focused on the single most important part of the experience - which was also the single most complex part of the product, and the make-or-break for if the product was feasible. We got to a point where it looked like it would be possible, and I could frame what it’d need to take forward - to “paint the rest of the owl“, as I described it to the client.
Hergest covered a fun technology stack: an app-like UI in the browser, using a reactive web framework; on-demand audio rendering using Google Cloud Run; loading media from disk without sending it across the network thanks to the File API; and working with Tone.js for audio functionality in the browser. It’s remarkable what you can do in the browser these days, especially in contexts where such rich behaviour is appropriate. In a few weeks of prototyping we got to an end-to-end test that could be evaluated with users, to understand demand and needs without spending any more than necessary.
Lowfell has slipped a little, which is on me: there was some issues with UPS shipping, and then pre-existing commitments managed to steal a lot of my energy. I’m hoping to resolve this in the coming weeks, but I did at least get a second prototype shipped and a 1.0 firmware built and signed off.
There was more teaching. I returned to be industry lead for the Hyper Island part-time MA, and spent some good days with an international crew delivering some lectures and coaching them on their briefs - this time, a particularly interesting brief delivered by Springer Nature. The students really got stuck in to the world of scientific publishing; a shame we were still delivering remotely, but not much else could be done there. I also am teaching at CCI again, delivering Sound and Image Processing for first year Creative Computing undergrads for one morning a week, through to the summer.
Finally, in Q1 I kicked off a three month project working with Normally. A team of three of us worked on a challenging and intense public sector brief. Gathering data, performing interviews, sketching, and prototyping; we spent 12 busy weeks exploring and thinking, and I was personally really pleased where the final end-to-end prototype we shipped - as well as the accompanying thought and strategy - ended up. It was great working with Ivo and Sara, as well as spending time in the wider Normally studio, and perhaps our paths will cross again. It was a great start to the year, but pretty intense, and so I didn’t have much time outside it for reflection.
What’s up next?
Two existing projects need wrapping: firstly, finishing up term at CCI and marking some student portfolios, and also wrapping up Lowfell.
Secondly, I’m going to spend the summer working with the same crew inside Google Research that I worked on Easington with, on a interesting internal web project. Not a lot to be said there, but it’ll keep me busy until the autumn, and I’m looking forward to working with that gang again.
And so, as ever: onwards.
Worknotes, Autumn 2021 edition
8 October 2021It’s autumn. What’s been going on since I last wrote?
Teaching at UAL-CCI
I wrapped up a term of teaching a single module at UAL’s Creative Computing Institute.
Sound and Image Processing is a module about using code to generate and manipulate images, video, and sound. The explanation I use in the first week is: we’re not learning how to operate Photoshop, we’re learning how to write Photoshop.
The course worked its way up the ladder of abstraction, starting with the representation of a single coloured pixel, through to how images are just arrays of pixels (and video, similarly, just a sequence of those arrays). We covered manipulating those arrays simply - with greyscale filtering - and then more procedural methods such as greyscale dithering and convolution filters. We could then apply this approach to sound, too, starting by building a sound wave, sample-by-sample, and then looking at higher-level manipulations of that sound wave to make instruments and effects. Finally, having already looked at raster graphics, we looked at maniuplating vector-graphics in real time to produce animation, particle systems, and behaviour, culminating in implenenting Craig Reynolds’ Boids and creature-like simulation.
This was quite demanding: it was my first time teaching this material, which meant that before I could teach it to anybody else, I had to teach it to myself in enough depth to be confident tackling questions beyond the core material, and to be able to explain and clarify those basics. Perhaps that’s a lack of confidence showing - a kind of perfectionism as a way of hedging against coming up blank - but as the term went on, I relaxed into it, and found a good balance between preparation, delivery, and the collaborative process of teaching and learning.
And, of course, it was almost all taught entirely remotely. The students did admirably given that awkward restriction - some of them may only have been coding for a single term prior - and they delivered a great range of work in their portfolios. I’ve said yes to teaching the course again next year; whilst I greatly enjoy my commercial work, teaching aligns strongly with my values, and it’s a rewarding way to spend a small amount of time each week.
Ilkley

The Ilkley revision B 'brain' board, with a Teensy 3.6 attached. Ilkley has continued to run on for the spring and summer. Last I wrote, I’d just received the first Ilkley prototype board. Six months later, there have now been several more prototypes - three versions of the ‘brain’ board, and two of the upper control board. The second brain revision is the one we’re sticking with for now - the third was a misfire, and really, a reach beyond the needs of the project. By contrast, the control board was fine first time; the second version of was primarily about fitting the components in an enclosure better.
The firmware has been more stable, largely being fine out of the gate. The ongoing work was primarily about finesse, rather than wholesale replacement, so I’m pleased with that.
As I write, I’ve just packaged up five prototypes to send to Matt in New York, which wraps up the end of this phase of my work on the project. The device works end-to-end, and is ready to be played with by test users. I look forward to hearing about his results.
Wrekin
In the summer I began a new piece of work that we’ll call Wrekin, working with a very early-stage startup on building a functioning “experience prototype” to validate their product idea with real users.
This was very much a prototype in the mould described in Props and Prototypes. Some of the prototype had to be 100% working, as we wanted to evaluate certain ideas in a real implementation, to see if the technology was up to scratch, and if users liked it. One other key idea was, though core to the product, largely proven: a ‘known known’. Wwe could get away - for now - with a “stunt double” version of the idea. And then a few more pieces of the prototype were, whilst functioning, only for the experience test; they’d be thrown away in due course.
Over the course of a couple of 2-3 week phases, I built out a feasibility study, that then turned into a deployed prototype, and shipped that to the client for them to test. It’s been a fun project - some interesting boundaries of what you can do with realtime video and WebRTC - and I’ve continued to work with the client on planning future technology strategy, and, if all comes to plan, turning the experience prototype into an end-to-end one that demonstrates all pieces of the puzzle.
It’s also been a project where work on features and design concepts has directly informed future strategy. Not just thinking about what’s possible, or what is desirable, but also understanding the value of build-versus-buy for certain functionality, and for starting to explore the “what-ifs” - the unknown unknowns - that emerged as we work.
I’m continuing to advise the Wrekin team, and may be working with them a little more in the coming months.
Lowfell
Finally, Lowfell. this is another hardware project: a commission for a custom MIDI controller for an LA-based media composer, who works in film, games, and TV.
The controller itself has few features. A few people I’ve shown it to were a little underwhelmed! But the brief for the project was never about complexity.
What client wanted, really, was an axe - a “daily driver”. Something sturdy, beautiful, and not drowning in features: that just did what they need it. They were going to be looking at this thing every day, for eight or more hours a day. They didn’t need RGB lights or tons of features they weren’t going to use; just the things they did want, in an elegant and suitably-sized unit. It’s the same reason we spend a lot on a chair, or a monitor, or an expensive keyboard (or on good tools, or good shoes): you use them a lot, and it’s worth investing.
Also, they didn’t want just one: they wanted one for each setup in their studio space, making it easy to move between workstations and to keep going.
The project began slowly. We did lots of conversation just exploring the idea, and I sent some paper mockups as PDFs over email to give the client a feel for what the size of the unit would be. Once we were happy with the unit, I built a first version, with fully working electronics, and a prototype enclosure that used PCB substrate - coated fiberglass - for the panels, with the sides of the case produced on my 3D printer.
This was enough for us to evaluate functionality and features. I made sure it was trivial to update the firmware on the unit, so I could send over fixes as necessary. (In this case, because we’re using the UF2 bootloader, updating the firmware just requires holding a button on as the controller is connected; this mounts a disk on your computer desktop, to which a new firmware file can be dragged).
Whilst the client evaluated the project, I started work on final casings: using higher-quality printed nylon for the sides, and moving to bead-blasted anodized aluminium for the upper and lower panels. The result is weighty, minimal, and beautiful, and I’m looking forward to sharing more when the project is complete.
Wrekin was my main focus this summer. Ilkley and Lowfell wrapped around it quite well: the rhythm of hardware is bursty, with prototypes and design work alternating with the weeks of waiting for fabrication to come back to me with the things I can’t make myself.
What there’s not been a lot of, of course, is writing. It has fallen out of my process a little. Not deliberately; perhaps just as a byproduct of The Times, coupled with several products that were either challenging to share news on in progress, or in the case of ones with NDAs, impossible.
But: a decent six months. Up next is, I hope, shipping a final version of Lowfell, some more software development for Wrekin, and a potential small new web-based media project on the horizon. I’m on the lookout for future projects, though, and always enjoy catching up or meeting new people, so if you think you’ve got a project suited to the skills or processes I write about here, do drop me a line.
Worknotes for March 2021: 'What is this prototype for?'
23 March 2021Last week I sent all the files necessary to build the first draft at my Ilkley prototype to China. That means the plotting files to make the circuit boards, the list of all the components on them, the positions of all the components. The factory’s going to make the circuit boards and attach most of the components for me.
This is good, because many of the components are tiny.
The Ilkley prototype is on two boards: a ‘brain’ board that contains the microcontroller and almost all the electronics, and a separate ‘control’ board that is just some IO and inputs - knobs, buttons. I am focusing on the brain right now: its “revision A” board is the right size and shape to go in our housing; the current prototype of the control board is just designed to sit on my desk.
About six hours after I sent it all off, I got an email: I’d designed around the wrong sized part. (I’d picked a 3mmx3mm QFN part instead of a 4mm square part, because that’s what had been auto-selected by the component library). This meant they couldn’t place the part on the board: it wouldn’t fit.
“Should we ignore the part and go ahead with assembly?“
At this point blood rushes to my head. That part is one of the reasons I’m not building it myself: it’s not really possibly to attach with a soldering iron, and I don’t have a better tool available at home. So maybe I should quickly redesign around the right part? I hammered out a new design in Kicad.
But now I’d have to send new files, new placements over, and probably start the order again. This was going to add delays, might not even be accepted by the fabricator, and so on.
Deep breath.
At this point, I took a step back, and had a cup of tea.
Over said tea, I made myself answer the question: what was this prototype for?
Was it only to test the functionality of that single chip that couldn’t be placed? The answer, of course, was no. There were lots of things it evaluated, and lots of things that could still be evaluated:
- many other sub-circuits - notably, a battery charger, a second amplifier, a mixer
- the integration with the ‘control board’ and the feasibility of my ribbon-cable prototype
- how several parts ended up being fitted, which the fabricator has not used for me before
- the fit/finish inside our final enclosure
- not to mention whether I’d made any other mistakes on the board.
So far on Ilkley, we have been lucky: every single first revision of our hardware’s worked. This doesn’t mean we’re brilliant at everything; it means nothing more than that we’re in credit with the gods of hardware. Something will go wrong at some point - that’s what
revision Bis for. All that had happened was I’d hit my first big snag.Prototypes aren’t about answering every question, but they’re rarely also about answering one. I usually teach people to scope them by being able to answer the question what is being prototyped here? - the goal being to understand what’s in scope and what is not. Temporarily, in the panic of a 4am email from China, I forgot to answer that question myself. It was good to be reminded how many variables were at play in that Revision A, if only to acknowledge how many things I have going on with that board.
I wrote back to the factory; ignore the part and proceed. We’d still learn a lot from the prototype, and revision B would contain, at a minimum, a new footprint for that 4mm QFN chip. I saved the hasty changes I’d made to the circuit board after the email in a new branch called
revision_b- which I’d return to working on once the final boards arrived.Worknotes - February 2021
24 February 2021It’s the middle of February, 2021. What’s going on since I last wrote, and what’s coming up next?
Wrapping up at CaptionHub
My stint at CaptionHub got extended a little, and I finally wrapped in the middle of February, last week. Everything went as well as I could have hoped on the overhaul of some fundamental parts of the codebase that I was working on.
I’m pleased with the decisions we made. It was good to review all the work with the team and agree that, yes, those decisions we took our time over and drew so many diagrams of were sensible ones, and it had been worth investing the time at the point in the process. We added more complexity in one location, but managed to remove it from several others, and I enjoyed the points where code became easier to re-use simply because we had standardised an interface.
A pleasure to be back writing Ruby, too; not just for its familiarity, but for just how it is constantly such an expressive language to work in and to write. And, of course, a pleasure to work with such a sharp and thoughtful development team.
Working with Extraordinary Facility
I started working with Matt at Extraordinary Facility around the end of January. Let’s call this project Ilkley for now. It’s years since I worked with Matt at BERG, and I was excited for the opportunity to work with him again. I enjoy his eye, taste, and process as a designer so much. You should definitely check out his recently published Seeing CO2 prototype for an example of his approach.
Ilkley is a physical product prototype. I’m taking a prototype that existed between hardware and computer software, and shrinking it into a dedicated box: porting all the code to run on a microcontroller, building the user interface, adding necessary extra hardware to make it entirely standalone… and then designing custom circuit boards to fit into an enclosure. That means: firmware, a bit of EE, some CAD, and then iterating software to get it feeling right. Leaping back and forth between the digital and physical, and code, electronics, and atoms; from pens and paper to alt-tabbing between code editors, KiCad, and Fusion 360. It’s been highly enjoyable so far.
I’ve appreciated the way Matt is laser-focused on the outcomes he’s looking for. The existing prototypes were the design work; this phase is entirely about bringing that design to life. Implementation, feasibility, and building a roadmap for the future. Until he can get more people to use it, it’s not worth us spending time altering anything else. We still go off on diversions and discussions, of course, as we chat things over, but they’ll get gently parked before they jump their place in the queue. It’s great to still have those discussions, though!
Our first tranche of work investigated whether what Matt hoped for was possible. The answer was an emphatic yes, and by the end of it, we’d gone from a large breadboard and tangle of jumper wires on my desk to a small, custom “bench prototype” PCB. Nothing that could fit into a box yet, but something I could reliably send Matt (in New York) to evaluate and test. (Which in itself helped me prototype the answers to “_how do we best ship prototypes across the Atlantic_”).
I also could then start prototyping other submodule circuits on breadboards, experimenting with them whilst not worrying about the main electronics, which were ‘frozen’ thanks to having a fixed design.
One top tip from this process: something that helped enormously was continuously maintaining an up-to-date schematic of the breadboard prototype as I worked on it. As I built the tangly prototype on my workbench, I also drew it up in KiCad, altering it whenever wiring changed, or resistor values were altered. The tangle got more complex as time went on, but this didn’t matter, because there was always a map of it available in the ECAD tool. When we were happy with the prototype I’d been demoing on video calls, it was easy to start the work to turn it into a PCB because I already had the schematic. I didn’t need to start deciphering the knot of wires; I could just put them to one side and move straight onto board layout.
I did exactly the same for the small submodules as I built them; those schematics would then be ready to use again for the first ‘full’ prototype.
Progress has been really good, and I’m going to start a second phase of work soon, to take the various sub modules and bench-sized prototype, and start turning it into an entirely self-contained object. That’s going to run over the next couple of months, I’d imagine, with some gaps to get things fabricated and pull things together.
Teaching at UAL CCI
Having wrapped at CaptionHub, and with at least one client project moving on, I’m also going to be teaching an undergraduate course at UAL’s Creative Computing Institute - the Sound and Image Processing module for students in the first year of their BSc. One afternoon a week, for the next three months.
Why teach? I’m not an academic, and don’t plan to become a full time researcher or lecturer. But I’m dovetailing a small amount of teaching around my client work over the past few years - Hyper Island, the IOC, and now this.
A few answers spring to mind.
Firstly, it’s a bit about the shape of the “industry” I work within. I’m a consultant and freelancer. How do I develop talent, or share my knowledge with others? I can’t do it with the other employees of my company of one. Sharing my knowledge with students and learners through teaching engagements is one way I can. Many of my peers who are located more within the Design community integrate teaching into part of their practice well, and whilst I often use the word ‘design’ to describe a lot of my work, ‘technology’ is also an important part of my practice - and ways of integrating teaching into technical practice is something I perhaps don’t see as much of. So I’m going to see how it goes.
Secondly, I find it a great way to cast a lens at my own practice. Nothing forces you to re-evaluate your own work, approaches, or knowledge, than having to explain or discuss ideas with others. Is it selfish to say that? I don’t think so; more just to reinforce that you can’t help but learn things yourself by going through the process of teaching.
And perhaps most importantly - I learn from all the students I teach. This is in part a reflected version of the previous point - yes, I learn by looking at my own understanding and reflecting on it… but I also learn from listening and sharing with others. Students and learners at all levels bring new perspectives, expertise, experience, and ways of understanding to the table, and I (along with the rest of the group) get to share in that with them.
All of which I value. So, an opportunity arose, to think about images and sound from first principles, and ways of exploring and explaining that. I said yes.
Which all feels like a good slate for now: prototyping design products; teaching about the landscape of code; a little slack between all that for reflection and personal development and work, which (at the end of a year that was already busy before being A Bit Much on top of it all) is much needed.
Onwards.
Worknotes - November 2020
20 November 2020I taught at Hyper Island this year for my fourth year now, as Industry Leader for the Digital Technologies module of their part-time Digital Management MA.
At the end of the course, I give a paper where I talk about personal process and practice. It’s a bit left-of-centre: not so much Best Practice, as Things I Have Found Useful.
I always tweak and rework the course a little each year. This year, I came to this paper, and found myself stuck. In it, I talked about the value of personal documentation:
READMEs in every project and code directory, so you can always pick up a thread after months away; weeknotes as a ritual and way of evaluating work. I talked about the value of colocation - why I prefer studios to offices, why the right people together in the right space is such a winner for work, and how precious a Good Room can be. And at the end, I self-indulgently talk about the value of reading fictionAt the beginning of September, I sat looking at the deck, and realised:
I am doing none of that right now.
Weeknotes, as you can tell, have fallen by the wayside. I’m Working From Home If Possible (and it is possible), not going up to my studio space. I’m working on projects on a succession of videoconferencing tools, all with their own quirks, and spending longer in my study than I’d like. I’m not reading as much fiction as I’d like.
I felt like I’d be a hypocrite to say these things to students.
In the end, I said it all anyway, dropping in a quick “recordscratch” sound effect to call myself on my own shortcomings, and to talk about the difficulty of espousing studio culture in an airborne pandemic.
It went down well, but it also turned out to be not as foolish an idea as I thought. By acknowledging the fragility of ideals in the face of reality, we could explore why I was recommending those practices in the first place. By challenging myself as to why I wasn’t following my own advice, I could explore what the point of that advice might have been.
The fact that I wasn’t writing at the moment didn’t mean that writing wasn’t a thing to recommend. It possibly meant that weekly notes were not quite serving a purpose now. After all, if I was busy, and getting the work done, and if the thing that fell by the wayside was talking about that, I might have to live with it, and work out how to change it.
For now, weekly notes might disappear for a bit. I’ll work out what replaces them in due course.
Meanwhile, let’s see where things are right now, in the middle of November 2020, and what’s happened in the past four months.
Easington
I delivered Easington in early September. I’d written about the project here previously; most notably, in this post on props and prototypes.
But then writing about it dried up. This was partly because having worked out what the job was, I mainly had to work on delivering that. Having done bunch of Thinking About Stuff, much of the work was Making Stuff and Explaining Stuff (sometimes both at once). There often wasn’t much more I could easily say here other than “yep, getting on with things“.
If you’ve read these notes for a while, you’ll know I’ve got all manner of ways of saying “yep, getting on with things“, but 2020 appeared to exhaust them.
It was also challenging because Easington was under an NDA, and the specifics of the project meant there was almost nothing I could say without revealing things my NDA forbids me from revealing. And given that, I was largely quite quiet.
What I can say:
Easington was a fourteen-week R&D project for Google AIUX, who work at exactly that intersection: the user experience of future AI-driven products. I worked closely with design colleagues inside AIUX, especially in London, but also spoke to researchers and topic experts from internal teams around the world. It was challenging and rewarding in equal measure. I’m proud of what we delivered.
It was also a project that almost directly mapped to what I laid out in March, when I wrote about what I do, before Everything Changed, and it was hugely rewarding to confirm that yes, that’s an excellent summation of my sweetspot.
Vacation
I went on vacation in the UK for two weeks after Easington ended. This was long-planned, and not an emergency “COVID holiday”. But I was very fortunate to be able to take that time off, and to do so in a safe and sensible way.
Teaching at Hyper Island
As mentioned above, I taught at Hyper again. Normally, this takes place in December and January of a year. However, as we were going to be teaching remotely this year, they decided to move my module to be the first the students took, not the second, and we delivered this in September and early October.
I reworked a lot of the material, and will write more about the specific nature of that reworking in the future, because I learned a lot about delivering material online.
In broad terms, we made everything shorter, denser, and with more breaks - lectures became more like “episodes”, nothing over 25m without a break. We also ran shorter days - 11-5pm, rather than 9-6pm, as we were all on Zoom for most of the day. In that reworking and condensation, I think I got to some of the best versions of those talks; condensation, and the clarity videochat requires, really helped to focus things.
I also coached the teams on their client project, and this time around it was exciting to see them embark on their first project, with no idea of where they could go, or what they could get done, in such a short space of time. Everybody’s pitches came out great, and it was a delight to meet so many new people. I say something similar each year, but I say it anyway, because it’s true.
I was also grateful to colleagues and peers we could invite in as guest speakers - to everyone who came, thank you.
A change of venue
As mentioned, I’m not really using my studio space at all at the minute: there’s just no reason to be commuting. By September, I realised that this was going to be a longer-term change. I’m lucky enough to have a private workspace at home, and with some rearrangement, it’d be suitable as a place to work from. So, with some sadness, I handed in my notice at Makerversity. I’ve been at MV for almost exactly five years now, and was greatly enjoying the new setup in Vault 7. But right now, I cannot justify the expenditure, given how little I need to be there. And so I’m going to say goodbye, and work from the home office for a bit. Not how I ever imagined I’d leave MV, and the excellent Somerset House community, but there you go.
A return to CaptionHub
Finally, in October, I returned to a three-month contract with CaptionHub. They had some extra work coming up on their slate and an extra pair of hands that knew the project would be welcome to help deliver it. Given the uncertain nature of 2020 - and, to be honest, 2021 - it felt like a no-brainer to take a three-month contract with them.
In one sense, this project is ‘just’ a software development gig. But it’s a particular kind of engineering I quite like: a careful, almost standalone set of features that need as much planning as they do implementation. I’ve been focusing on swapping out some of the underlying premises in the code, in order to support future features, which has led to a lot of diagrams and thinking before embarking on a careful switch from one shape of the world to another. I have described this as indianajonesing, in reference to the opening of Raiders of the Lost Ark (and I should note, this is not my metaphor - I just cannot remember where I got it from). In our case, I’m swapping one set of code for another, and making sure nobody notices the changeover, and no-one gets squished by a giant boulder.
It’s going well, although it takes a lot of my brain and concentration (which is not quite in the supply it was in 2019). That often means there’s not space for much else at week’s end (I’m taking Fridays as days for personal work). But good work, with a lovely, thoughtful team, is highly appreciated right now.
Appreciation is the right note to end on. I’ve been very lucky to be able to take on all these projects this year, in a time when work hasn’t necessarily been easy for everyone, and I’m always careful to acknowledge that when talking about my own practice.
Right now, I wanted to acknowledge where everything was, and share what I could about the last few months. I imagine worknotes continuing in perhaps a less frequent format for the coming weeks and months, whilst I get back in the habit, and maybe find new ways to share my practice.
What I concluded, talking to the students, was not the frequency, but the act. Some writing beats no writing.
And hence: some writing.
Weeks 391-393: Props and Prototypes
20 July 2020I wrapped up phase two of Easington. We completed the beta of our interactive game-like thing that we built to explain the output of that phase. The prototype evolved a lot during the phase. Probably the best thing that happened as it progressed was that things I’d initially described in text were extracted to state. That is to say, we made it more gamelike: rather than describing other possible outcomes of an action, why not find a way of letting the user alter the state of the world, and then see what happens when they repeat the action?
It sounds obvious when I write it down, but when I’m head down in the code, it is sometimes hard to have that high-level picture. This is one of the values of weeknotes: acknowledging what I missed, and writing it down so I don’t forget. Making the prototype more interactive - adding new interactions, and making it respond more richly to them, turned out to be the right answer every time. Something to remember for the future.
This phase of the project has had me thinking a lot about propmaking, and its relationship to protoyping.
Props in films aren’t just one thing. Think about a prop like, say, a lightsaber from Star Wars. A single prop lightsaber will likely exist in several forms, including:
- a “hero” prop, that’s seen in close dramatic scenes. Made of realistic materials (metal, plastic, wood), full size, detailed. Something an actor can act with, and respond to. Something that will look good on camera.
- perhaps: further hero props in different states: with the blade extended and retracted, for instance, or “damaged” and “undamaged”.
- perhaps a separate functional hero prop for specific purposes. Imagine a close-up scene where we see the hero dismantling their lightsaber and repairing it: that “dismantalable” prop might be entirely different to the hero prop seen most of the time. (It might even be a partial prop - just the parts you can see in shot, and extra things to make it work also attached)
- stunt props. These look almost identical to hero props, but are usually made entirely of foam rubber, and cast from the hero prop. These are used, as the name suggests, for stunts, where the object might be bashed around, or come into contact with an actor at velocity. They also end up being used for scenes where there’s any rough handling of a prop that might damage the prop itself - being thrown, or dropped, for instance. And frequently rubber props will used for background action, made en masse to give to extras, or used when the hero prop isn’t strictly necessary - when the lightsaber is hanging from the hero’s belt in a scene where it’s not really used, for instance.
- once upon a time, props might have existed as scale models - a miniature lightsaber on a stop-motion puppet, for instance. Scale models tend to be more common for large objects, like vehicles or buildings.
- the modern equivalent of a scale model prop is a CG version of it, to be used in computer-generated visual effects. The prop has a digital double, perhaps made from a 3D scan of the object.
And for some of those props, on a large film shoot, there will be duplicates and spares.
I’ve been thinking about the way one prop exists in multiple forms, and the different roles they all serve, because of all the different kinds of prototype I’ve built so far on Easington.
So far, we’ve made real working code and tools (out of Python/Javascript and Docker/Cloud Run, as well as modern front-end web stuff); an interactive, explorable prototype pocket world; browser-based prototype UIs; clickable prototypes in Figma; and sound and video prototypes made out of samples, synthesis, and video in tools like Ableton Live and Hitfilm.
And all of those prototypes are very, very different.
- Our working code makes a useful point about the current state of things, and lets other people explore the idea. But it’s not in any way production ready, and it falls apart a little if you don’t use it the way it’s intended. That’s our close-up, working-for-one-task prop.
- Our clickable mockups are like stunt props: they look highly convincing, fulfill a hugely important role, are highly robust, but the second you touch one you’ll discover it’s fake.
- Our video and audio demos are a lot like CG: entirely convincing, we can do whatever we want with them, but 100% fake - and not even interactive.
- Our interactive gamelike is a bit like a scale model: it has not just look/feel but logic as well, albeit in a highly constrained and limited way. It makes sense in its own little pocket universe.
Like props, none of these are exactly ‘real’, and none of them work outside the world of the project. But they all serve useful purposes, and like all the different prop lightsabers, they all work together to tell our story. Our scale models, clickable mockups and VFX are made convincing by the fact we’ve also shown genuine, working code, but in a rougher form. And they wouldn’t have the same impact if we didn’t have that “close-up” prototype.
The mockups and scale models help us invent and imagine, and help people using them imagine how the fragile working code might feel in the world, and in the near future.
The other thing I find useful about enumerating the different types of prototype we’re making is it helps me understand what their individual value is - and when they might be considered “done”. Because they’re all fulfilling different roles, they have different completion criteria. Some need to look very good; some need to function correctly; some need to be somewhere in the middle. Understanding what the prototype is trying to achieve in terms of its role, not just its functionality, helps me think about the right material to build it out of, the right level of detail to furnish it with, and when to put it down and move onto a different kind of prototype.
Weeks 389-390
29 June 2020Another couple of weeks with my head down on Easington.
It’s a challenging project to talk about, because of NDAs. But that’s somewhat the point of weeknotes: noting not only what I did, but how, and why. The job isn’t to share the details of what I was up to: it’s to share the parts I felt worth sharing as insights into process, or thought, or for me to remember in the future.
The project has moved to a new section of exploration, which is involving less prototyping of working code, and is more about explaining ideas, possibilities, and illustrating processes. Some of this fortnight’s work has been finding ways to do this that Aren’t Decks.
Slide decks aren’t inherently dreadful. They have a lot to recommend themselves as formats to encapsulate and preserve information. They combine images and words relatively well, they are often terser than long prose documents, and emerge not as a ‘primary’ artefact - “here is my research paper” - but as synthesis. That means they’ve gone through the mill a few times and are condensed, compact versions of an idea.
But. The “distribution deck” is still very different to a presented deck - or even a writer walking you through the deck they will later distribute. Decks are relentlessly linear, which makes conveying ideas that may only ‘click’ after prolonged exposure challenging.
A good narrative reinforces itself when it ‘clicks’ into place. The ‘aha’ moment for a reader shouldn’t be a single moment of discovery; it should also reverberate through each step of a narrative, revealing how they set up this particular ending. That may sound flowery and poetic, but it’s often true of research or design presentations: everything up to the reveal is preparing you for it. Of course, you are then either carried forward by the speaker without a chance to revisit it… or have to flick backwards through the deck.
This is not really how thinking works. The moment something clicks may be different for different readers, dependent on how they think, where their attention is, what ways of transferring knowledge work best for them. Less linear formats let people pace their discoveries, repeat segments in more natural manners than ‘rewinding a tape’, and make re-examining content through new lenses more natural.
In short: what are more interactive ways of delivering R&D that convey the experience of discovery, and a depth of understanding, better?
One thing that came up as we tossed this idea over was Ben Eater and Grant Sanderson’s work on explaining quaternions. Try the first video to see what I mean. It may look like a video, but it is, in fact, a choreographed interactive page. There’s a timeline, and narration, and the narrator has their own cursor… but it turns out they are playing with a webpage, and you can play with it too whilst they talk. They even pause to let you have a fiddle. And you can continue to explore when they’re finished. This is a technically complex way of delivering content (and it’s also technically complex content!), but it radically changes the learning process compared to a static video.
I am not making anything so sophisticated. But I am exploring formats more similar to Hypercard decks or hidden-object Flash games than just a PDF of a slide deck. To that end, I’ve been working with Phaser a fair bit. Ignore the ugly website: Phaser is, effectively, a Flash-like game engine for HTML5, via Canvas and WebGL. For me, it resembles Flixel a lot: an object-y, sprite-y game engine that lets you write ES6.
I mainly fell on this as the easiest way to play with the idea I had. As it turns out, I could probably do a lot of it in the DOM with modern Javascript, but there’s something about using a tool designed for games, rather than documents, that changes how I work a little, and it made building the prototype I was working on relatively swift. The prototype delivers information, but it also was a way of prototyping content delivery. Already we have something that has pacing, “beats”, and can be replayed or re-explored to meaningful results.
I am certain we will end up delivering a deck as well. I’m working on one now. But letting people explore an idea, rather than just reading about it, seems like an avenue worth pursuing further.