Swarmize
A data-journalism platform to help editors and journalists gather and share information at volume.
Swarmize is a platform to help editors and journalists gather data at volume, and in real time. It was funded by a Knight News Challenge grant, and developed alongside Graham Tackley and Matt McAlister.
Swarmize has a few core components:
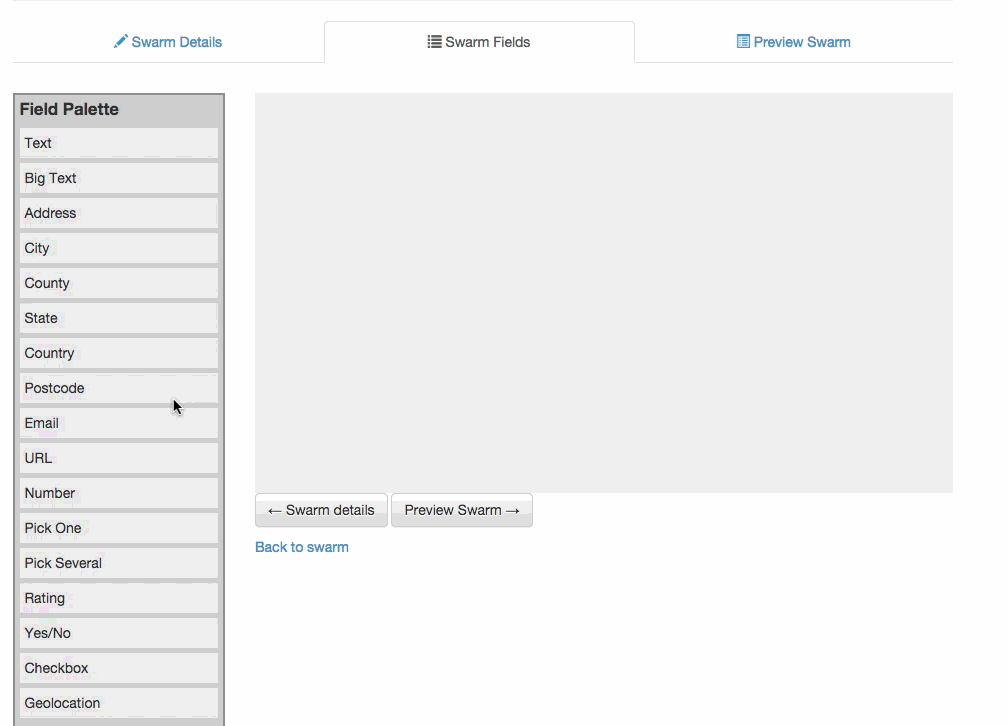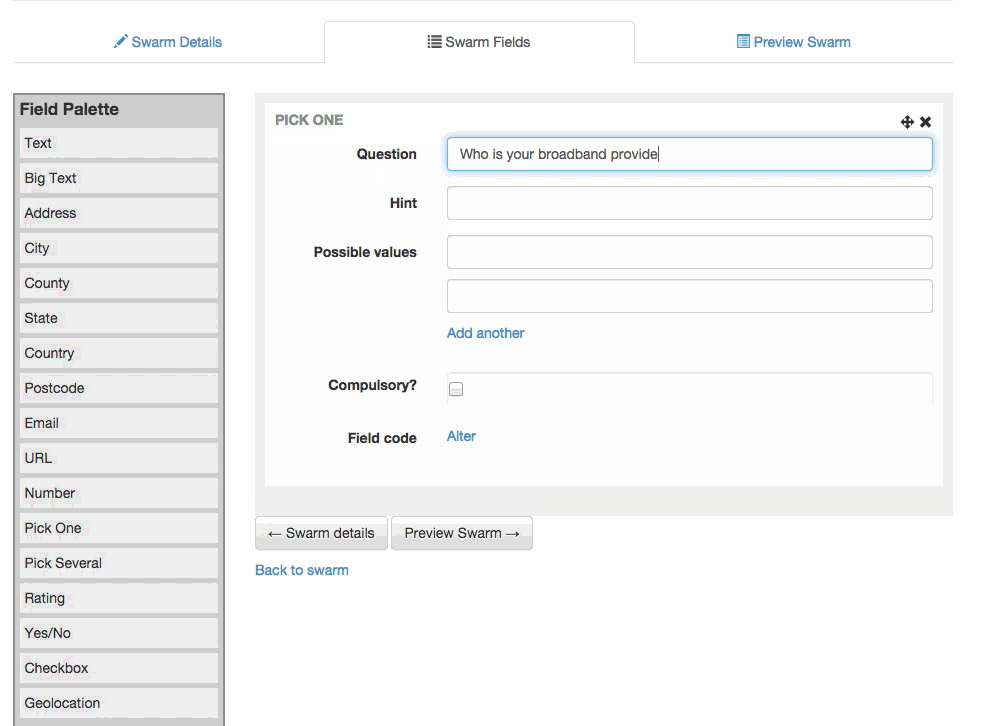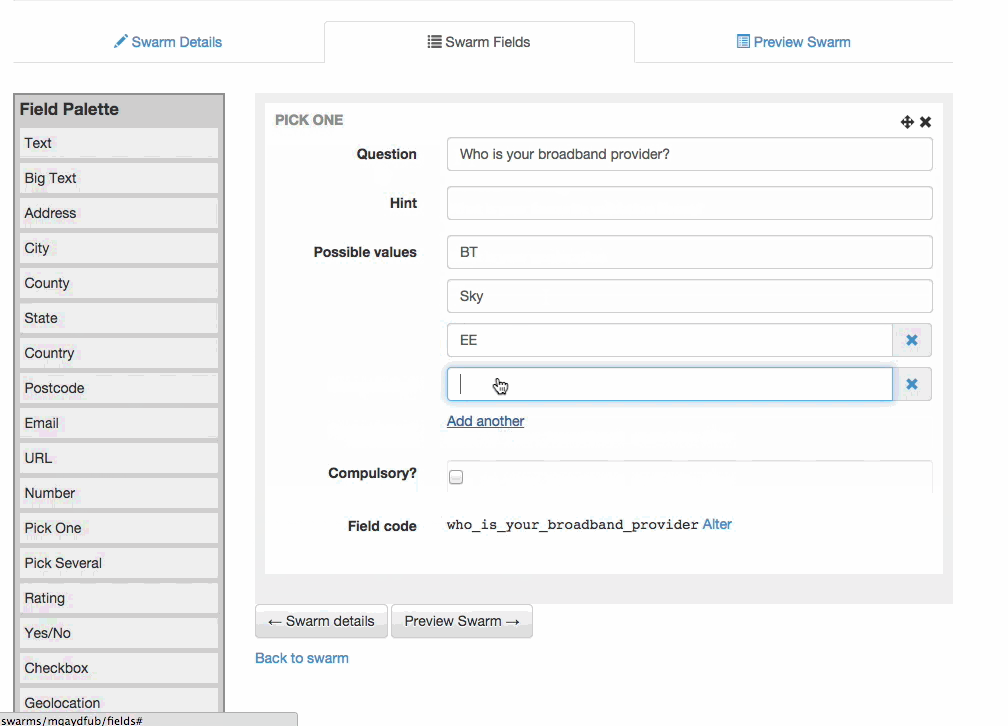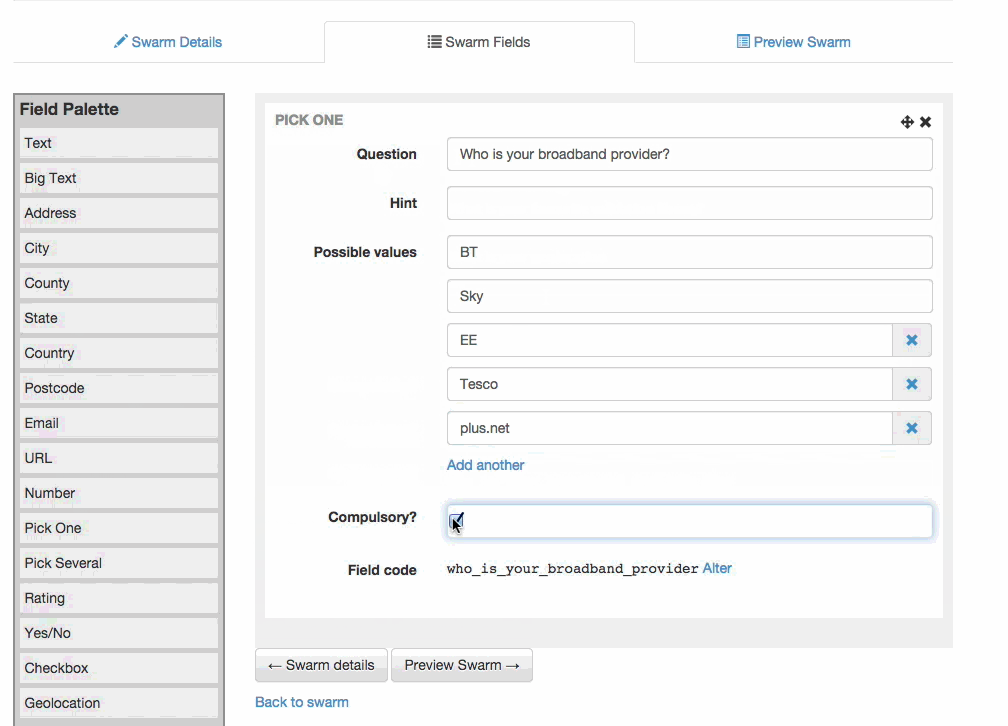
- Form building: "swarms" are initially designed by building a form. The form-builder encourages editors to think about the type of information they're gathering, rather than the HTML elements they might want. For instance, rather than a 'radio button' field, an editor would use a pick one of many field. These field types couple both to inline and back-end validation - numbers are checked to be numbers, minimum counts of checkboxes are enforced - and also to back-end processing - 'Postcode' fields are geocoded on the back-end.
- Form embedding: once a swarm has been created and set 'live', it can be embedded easily into any CMS or page. Javascript validation is included, although validation is performed when the data is sent to the back-end so it's very much cosmetic. The JS embed has no requirements of other libraries or components: it brings everything it needs.
- Input API: it's easy for a front-end developer to replace the form with any HTML or Javascript they want - there's a single page for each swarm that specifies all field names and possible values, and allows developers to generate API keys. If you can describe your data as a series of questions, Swarmize can be a generic back-end for that data at volume.
- Storage: once data is submitted to Swarmize, it's pushed through a processing pipeline before being stored in Elasticsearch. Different field types can have different post-processing routes, and they're easily extensible. This makes doing geocoding, or location-derived information (such as also storing counties, identities of local representatives) a straightforward extra for developers to offer.
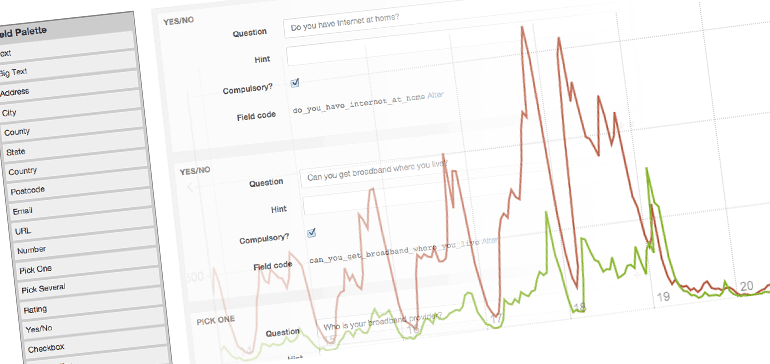
- Dashboards: Once a swarm is live, its dashboard page will show its team information in realtime, both as a table of top data, and also via customisable charts.
- Export: Of course, the whole dataset can be exported as CSV at any point.
- Sharing and collaboration: a swarm is initially private to the editor who created it. It's easy to give permission to other members of staff, and invite them to the swarm, where they can view the information or finish creating it for you - reflecting the reality of how teams work.
- Cloning: any swarm can be cloned. Cloning a swarm creates a copy of its survey, assigned to the user who created the clone - but with a new, blank data table. That makes it easy for editors to copy swarms they want to use as a starting point, or perhaps to run longitudinal surveys, updating the same set of questions every month.
The Swarmize website features three comprehensive case studies with animated explanations:
- A simple example, showing how to produce a traditional embedded survey to go into an online article.
- An example of API usage, showing how simple it is to produce a real-time 'clicker' for feedback during televised debates
- Documentation of a swarm we created to track sentiment around the Scottish independence referendum, piping Twitter search results straight into Swarmize, to gather 90,000 data points in a week.
Working onsite at the Guardian meant that frequent collaboration and discussion with journalists and editors was possible, and the feedback we received was invaluable.
Throughout the build of Swarmize I worked closely with Graham - the only other developer on the project. My focus was primarily the Rails-based web front-end for creating managing, and viewing Swarms. I also produced the documentation for both case studies and for other developers. This code all integrated with the Scala-based back-end pipeline, which dealt with everything from validation and storage through to API retrieval. We used a stack comprised of a variety of AWS components - Elastic Beanstalk, RDS, DynamoDB, Simple Workflow - and built our own deployment tools.
You can find out more at swarmize.com, and the code is publicly available on Github.